Are Frameworks Keeping Up With Modern API Requirements?
Over the years I've used about 20 different web application frameworks (tool-kits for making server-side applications), contributed to a few, and maintained a couple of popular ones. I've got a bit of a theory that many developers are introduced to new methodologies as and when their framework deliver it to them.
Whilst this might sound like cargo-cult culture, I get it, developers are busy people. User manuals showing how to do DDD, TDD, Event Sourcing, or whatever, is much easier to understand in the context of a framework you're already familiar with.
These days many frameworks are either primarily designed to create APIs, or have an "API mode" to cut out non-API related bootstrapping, for cookies, sessions, views, etc.
We all know technology moves fast, but the world of API development has changed drastically, and quickly too. Many web application frameworks never solved the API problems of the HTTP/1.1 era particularly well, and forced a lot of work onto the application developers which could have easily been solved with some built in convenience methods. With HTTP/2 mature and widely available, and HTTP/3 coming out soon, there is a lot more they could be doing to help. Some still don't have HTTP/1.1 particularly well covered.
For example, back in 2009 I released CodeIgniter REST which is now being maintained by Chris Kacerguis. I was wrong about what REST was back then. I misunderstood the Richardson Maturity Model and thought it was JSON over HTTP. I added that to a framework which surprisingly was pretty bad at handling HTTP in general: no query string support, only GET/POST supported, etc.
These days pretty much all frameworks support "HTTP routing", query string, JSON, etc. by default, and it would be considered shocking if they didn't. Until then everyone was hacking it in on their own, but sadly API developers are still having to hack together support for a lot of these fundamental concepts:
Let's look at some of this stuff. Maybe your framework can do it, or maybe you'll get inspired to send them a pull request. 😎
Serialization
When it comes to output, many frameworks seem to offer you a JSON helper, but don't do much more. Creating an API response should not just be a case of "I have an object, now it's a JSON object", because that is how you built brittle trash APIs which just dump the DB model to the consumer.
Serializers are important, and are essentially a "view" for resources. They let you pick and chose which fields should be output, combine fields, compute extra fields (not always great), and maybe even convert some numeric enum values into human readable labels.
Laravel has serialization logic built in, and Symfony has a component too.
The best serializers go a step further and offer support for common "message formats" like HAL, JSON:API, JSON-LD, or Siren. A message format goes beyond just being JSON, and standardizes the shape of collections, resources, metadata, error messages, and links for things like state changes, pagination, etc. This stops developers having to bike-shed the small stuff and make poor decisions, and means a whole chapter in Build APIs You Won't Hate can be skipped.
A framework that cares about APIs does not need to support every single message format, but the serializer should be extensible so different formats can be plugged in. A good API should be able to support multiple formats easily, and that's not really possible with any framework I know of at the moment.
Figuring out which serializer to use for many frameworks can be hard. Some serializers are fast but only support one format (like fast_jsonapi), some support multiple formats but are slow (like ActiveModel Serializers), and some have fallen into disrepair (also AMS).
- Fractal for PHP
- Roar for Ruby
- Marshmallow for Python
These are all agnostic tools which require a bit of boilerplate to get running in most frameworks, but I think frameworks should be doing the integration with these tools, or providing the equivalent functionality. API Platform offers JSON-LD and HAL with its serializer.
Standard Errors
A surprising number of APIs will emit HTML error messages which confuse the API consumer; they just see "Invalid JSON token <" and no further explanation until they dig into the network traffic...
Most of the remaining frameworks which do output JSON for errors will just go ahead and invent their own rando-JSON error format, or expect users to create their own.
{
"ErrorCode": "CATALOG_NO_RESULT",
"Description": "Item does not exist"
}
However they spit out internal errors, frameworks should provide high quality error serializers so users don't find themselves dumping return json({ error: "something went wrong" }). How many APIs have you worked with where this is thrown at you?
{
"error": "something went wrong"
}
Over time those developers realize they need programmatic codes, longer explanations, links to problems, and all sorts of other things. Creating good quality error messages is not easy, and frameworks should support this by supporting common error formats.
config.error_format = "rfc7807"
config.error_format = "json:api"
config.error_format = do |errors|
errors.map do
# ... some custom shit
end
end
Supporting RFC 7807: API Problems and JSON:API Errors would mean consistent error outputting for every API response, increase the chances of consistent errors across that organizations API portfolio, and remove a lot of guesswork for API consumers.
Deserialization
I built Fractal to serialize, and whenever people asked why it couldn't deserialize too I answered that serialization and deserialization were two different jobs. I've been wrong about a lot of things and this can go on the list. Serialization and deserialization share the concept of a "contract" (i.e. all the attributes that make up the resource in question), and turning them from the resource into message format compliant JSON is just as important as reading that inconing message format compliant JSON and turning it into a resource.
In Rails for example, ActiveModel Serializer will give you all the help in the world to output stuff as JSON:API, but when you're trying to read that data back you're stuck with mucking around with Strong Parameters
params.require(:data)
.require(:attributes)
.permit(:title, :description)
The bigger the resource the more complex this syntax gets, especially if you have an array of objects in the payload where some of the objects attributes are required and some are not...
Trailblazer is a collection of gems that make Ruby-based frameworks better at being an API framework, and offer serialization and deserialization through a shared contract. It also comes with support for popular message formats. There are a few gaps in the documentation here and there but you can usually find what you need from digging around.
Google have a Golang JSON:API serializer/deserializer, which uses annotated structs.
type Blog struct {
ID int `jsonapi:"primary,blogs"`
Title string `jsonapi:"attr,title"`
Posts []*Post `jsonapi:"relation,posts"`
CurrentPost *Post `jsonapi:"relation,current_post"`
CurrentPostID int `jsonapi:"attr,current_post_id"`
CreatedAt time.Time `jsonapi:"attr,created_at"`
ViewCount int `jsonapi:"attr,view_count"`
}
type Post struct {
ID int `jsonapi:"primary,posts"`
BlogID int `jsonapi:"attr,blog_id"`
Title string `jsonapi:"attr,title"`
Body string `jsonapi:"attr,body"`
Comments []*Comment `jsonapi:"relation,comments"`
}
type Comment struct {
ID int `jsonapi:"primary,comments"`
PostID int `jsonapi:"attr,post_id"`
Body string `jsonapi:"attr,body"`
Likes uint `jsonapi:"attr,likes-count,omitempty"`
}
So much of the training and writing that I do could be thrown out if more people used existing standards, and way more people would use them if their frameworks made it easy to do so. Those who are using them would appreciate the simplification for their code too, so it's a win win for everyone.
Validation
Deserialization and validation are often blurred together in some frameworks. Deserialization in APIs is just turning what is coming over the wire into something understandable, then the validation logic checks to see if the data is any good. Trying to do both these things in the same interface is rough, and rarely works out well.
Validation logic doesn't want to know about JSON:API, and trying to shove "this field should match this regex" and "should also be unique in the database" into the deserialization logic just makes for a big old mess.
To go with another Rails example, Strong Params is for kinda deserialization, then the validation usually happens in the model. Models are a tricky place for validation, for more on that search "Skinny Model,
The solution for some tooling is to make a validation contract file, which just does the validation.
class NewUserContract < Dry::Validation::Contract
params do
required(:email).filled(:string)
required(:age).value(:integer)
end
rule(:email) do
unless /\A[\w+\-.]+@[a-z\d\-]+(\.[a-z\d\-]+)*\.[a-z]+\z/i.match?(value)
key.failure('has invalid format')
end
end
rule(:age) do
key.failure('must be greater than 18') if value < 18
end
end
This moves it out of the model or controller (all of which has pros and cons for other articles), but this is yet another place where people are having to write out their contracts. API Developers already maintain the API contract in the following places:
- (De-)Serializers
- HTTP Clients (like Postman)
- Contract Testing
- Documentation via OpenAPI
When you ask developers to do the same thing so many times over, some of it is going to be low quality. Instead, I have spent the last 18 months trying to figure out how to reduce the amount of repetition for API developers.
That last one, OpenAPI... looks a bit like this.
type: object
properties:
username:
type: string
email:
type: string
format: email
age:
type: integer
minimum: 18
required:
- email
- age
This is a usable contract which can totally reduce the requirement for needing to write out that validation contract. Just take the OpenAPI file, and validate it on the server side. If the error format is RFC 7807 or JSON:API Errors then it doesn't matter if the error came from the OpenAPI validator, or the controller, or some database-based uniqueness exception being thrown from a race condition, it all looks the same.
A framework could easily build logic where serializers and deserializers take a contract, and that contract could be their usual DSL, or it could take an schema object to reduce the amount of typing. I wrote about how API developers can already use OpenAPI for server-side validation, but it shouldn't be something folks need to hack together.
Anyone who used to think writing OpenAPI was hard was probably doing it before Stoplight Studio came out. We've made API Design-first not just possible, but incredibly easy. With more and more people starting to create API descriptions before they write code, frameworks can leverage this description as a contract to help folks get running code much quicker. Design-first OpenAPI is the most important thing for API developers and it should be supported as a first class part of any API framework.
HTTP/2 + Server Push
One of the biggest fundamental changes in ye oldé APIs of HTTP/1.1 is the concerns of "lots of HTTP calls" leading to API developers mushing loads of JSON together.
Several API formats and architecture including GraphQL, JSON:API and HAL try to solve the under-fetching problem by allowing the client to ask the server to embed related resources in the main HTTP response. Basically, the server will create a big JSON document containing the main requested resource and all its requested relations as nested objects. This solution aims to limit costly round-trip between the client and the server, and is (almost) the only efficient solution when using HTTP/1. However, this hack introduces unnecessary complexity and hurts HTTP cache mechanisms. Also, it isn't necessary anymore with HTTP/2!
-- Kévin Dunglas, Vulcain.
Even though HTTP/2 was published in 2015, most frameworks only support the most basic bit: multiplexing. Nothing is required of a framework to support multiplexing, it's a network-level feature enabled by the client, web server (nginx), application server (rack, unicorn, etc.)
Multiplexing changes a lot for API design, and limits the cost of under-fetching, but the more interesting HTTP/2 feature for API design and development is Server Push.
Server Push lets API developers solve over-fetching, having them design more simple resources and move related content out to other endpoints, which can be pushed to the client preemptively if they're likely to want it (or if they specifically asked for it with the Preload request header).
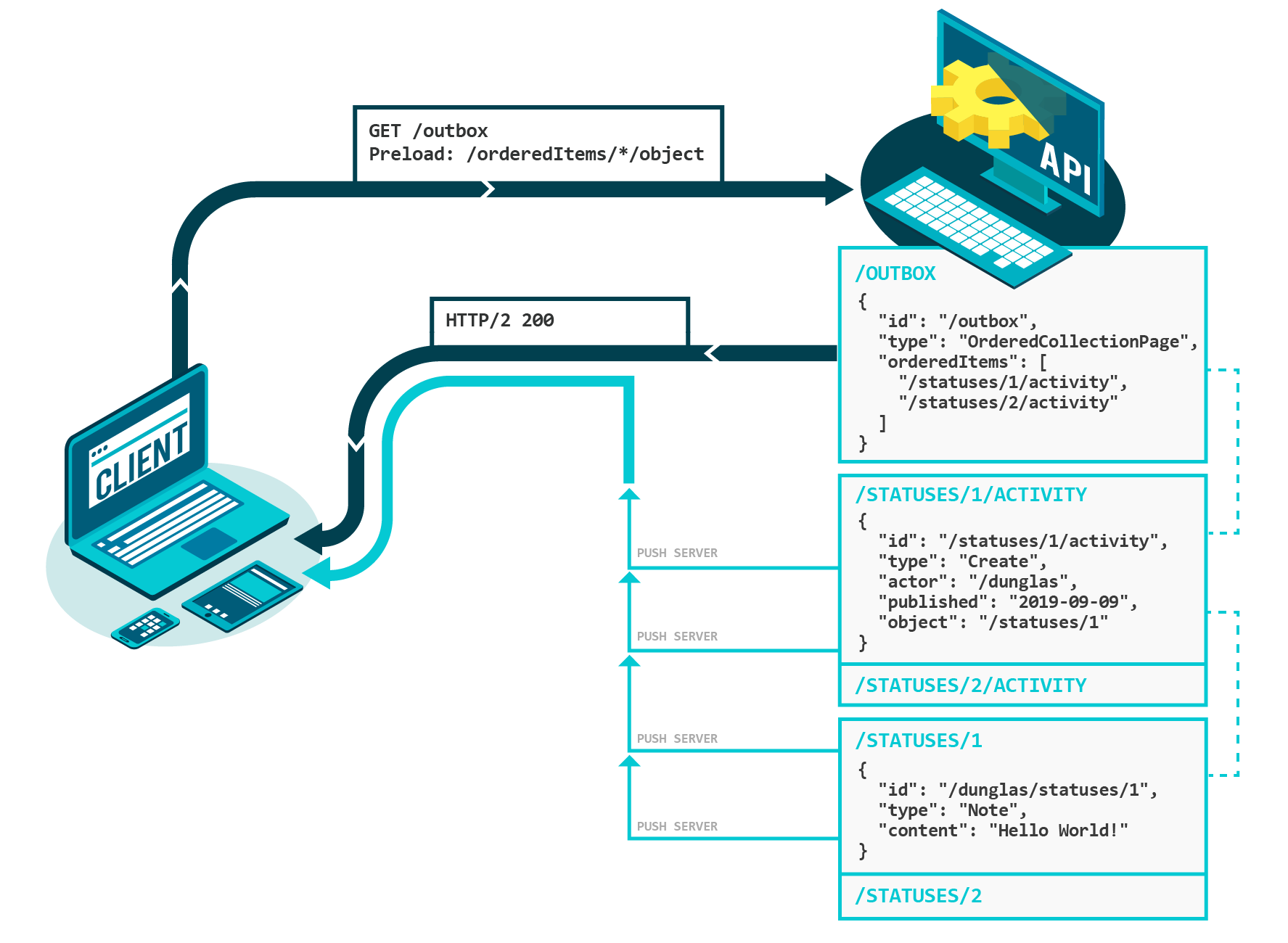
API developers back in the HTTP/1.1 days would include every tangentially related resource in a single response to avoid clients having to make multiple requests, and this was slow and annoying for clients who didn't need that extra data. If some of that data was computed, or highly volatile and therefore tricky to cache, the whole resource would be slow every time, instead of it being broken into some cacheable and some uncacheable resources.
For example, at my previous employer, the /users/fred resource contained all of their locale information, various public profiles, information about the company they worked for, subscription information, which buildings they had access to, and other information about those buildings. The subscriptions and building information were both fetched from other APIs which were down half the time, and even when they were up they were slow, which effected the performance of this API, and... heh that company is a book in and of itself...
Anyway, this was all jammed in there each time a new client asked for new information because "aggghhh multiple requests! 😱" but with server push, the buildings, subscriptions, locale, etc are all their own resources. Clients still make requests for the same related resources, but thanks to server push those responses will be sat in the clients push cache before they even thinks about asking for them.
Rails edged towards HTTP/2 support by adding Early Hints in v5.2, which seemed like a step towards server push, but no progress since. Ruby is a tricky situation, because it became web-aware later on through projects like Rack, which everything now relies on. Rack does not support HTTP/2 yet. Despite the existence of Falcon, a HTTP/2-enabled Rack compatible application server, Rails still has no server push...
Despite not being a "framework", Golang has server push support because it's written its own HTTP layer. Eyal Posener wrote a great example in this post showing how server push works for an API:
func handle(w http.ResponseWriter, r *http.Request) {
// Log the request protocol
log.Printf("Got connection: %s", r.Proto)
// Handle 2nd request, must be before push to prevent recursive calls.
// Don't worry - Go protect us from recursive push by panicking.
if r.URL.Path == "/2nd" {
log.Println("Handling 2nd")
w.Write([]byte("Hello Again!"))
return
}
// Handle 1st request
log.Println("Handling 1st")
// Server push must be before response body is being written.
// In order to check if the connection supports push, we should use
// a type-assertion on the response writer.
// If the connection does not support server push, or that the push
// fails we just ignore it - server pushes are only here to improve
// the performance for HTTP/2 clients.
pusher, ok := w.(http.Pusher)
if !ok {
log.Println("Can't push to client")
} else {
err := pusher.Push("/2nd", nil)
if err != nil {
log.Printf("Failed push: %v", err)
}
}
// Send response body
w.Write([]byte("Hello"))
}
NodeJS has Server Push support too:
const http2 = require('http2')
const server = http2.createSecureServer(
{ cert, key },
onRequest
)
function push (stream, filePath) {
const { file, headers } = getFile(filePath)
const pushHeaders = { [HTTP2_HEADER_PATH]: filePath }
stream.pushStream(pushHeaders, (pushStream) => {
pushStream.respondWithFD(file, headers)
})
}
function onRequest (req, res) {
// Push files with index.html
if (reqPath === '/index.html') {
push(res.stream, 'bundle1.js')
push(res.stream, 'bundle2.js')
}
// Serve file
res.stream.respondWithFD(file.fileDescriptor, file.headers)
}
The frameworks for Go and NodeJS have a lot done for them, so they just need to make this pushing a little easier, maybe add some helper methods, and hook it up with their serialization logic.
Network Caching
Network caching is a big complex topic which Ruby on Rails has managed to make incredibly easy. Firstly it's super simple to tell the API to do a time-based expiry. Here's an example in Heroku's article HTTP Caching in Ruby with Rails.
def show
@company = Company.find(params[:id])
expires_in 3.minutes, public: true
# ...
end
Adding that will emit a Cache-Control and set the max-age to 180.
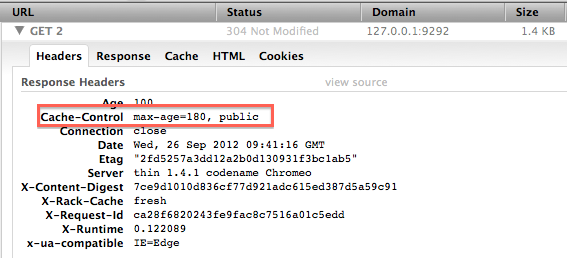
The basic time-based caching is not the exciting thing here, the best bit is the stale? method.
def show
@company = Company.find(params[:id])
if stale?(etag: @company, last_modified: @company.updated_at)
@company.employees = really_expensive_call(@company)
# ...
end
end
The stale? method here is checking for conditional headers like If-Modified-Since and If-Match, which as well as helping to avoid race conditions on writes, can provide caching for reads.
This is a verbose usage which works with anything, Company could be any sort of instance at all, but if it happens to be an ActiveRecord instance (or something similar enough) it can be simplified to if stale? @company.
These things can also be combined.
def show
@company = Company.find(params[:id])
expires_in(3.minutes, public: true)
if stale?(@company, public: true)
# …
end
end
To understand the benefits of HTTP caching for clients, take a look at my article Speeding Up APIs/Apps/Smart Toasters with HTTP Response Caching, and for more on the whole topic check out this talk.
If a web API doesn't have any caching helpers built in, it's not particularly useful to API developers, regardless of if they are building a HTTP API or a RESTful API.
Summary
When I'm looking for a framework to use, I see how much of this I can get done, as any API I build is going to need HTTP caching, HTTP/2 with server push, serialization, deserialization, OpenAPI-based validation, standard error formats, and support for message formats like JSON:API. If there is not first-party or third-party tooling around which solves these issues, I am going to recommend another framework that does.
Not everyone spends as much time thinking about API development solutions as myself, and I get that. Many developers might have not heard of some of these concepts. Other developers may be familiar, but unsure how to implement them easily. Some developers might not want to introduce an advanced concept that their less experienced colleagues will struggle with. This is where frameworks have always shone, helping less experienced people do more advanced stuff with a simple, well documented interface.
Maybe we see more API-specific frameworks emerging, and the more generalist web application frameworks continue the way they are. That said, with the growing trend for API-first development, more and more backend developers switching to primarily API development. I feel like the need for generalist frameworks is somewhat in decline, meaning the need for proper API support is going to be more important now than ever.
Check out API Platform if you're interested in a toolkit which is all about APIs. It's based on Symfony (a PHP framework), supports HTTP/2, GraphQL, and Vulcain. If you're a Ruby fan check out Graffiti which helps you make graph APIs with JSON:API and GraphQL at the same time.
Open-sourcing is hard and time consuming, so if you'd like to see some of this in your framework of choice, please consider pitching in! I'm out of the framework maintenance game these days, busy building API design tools at Stoplight, but I know framework developers appreciate help far more than they appreciate demands. 😅